
辞書の限界とその攻略法 !(「通訳・翻訳ジャーナル」 2000 年 4 月号記事) 以下は、2000 年 4 月号の 「通訳・翻訳ジャーナル」 に掲載された特集「辞書の使い方」 に寄稿したものです。 1943 年生まれ。東京外国語大学インドネシア語科卒。卒業後、外務省に入省。アイルランド、インドネシア赴任を含めて 8 年間勤務。退官後、鋼材専門商社に入社、インドネシア支店を設立し支店長として 7 年間、インドネシアの現地法人の副社長として 2 年間、さらに日本の機械商社のロスアンゼルス支店を開設し、支店長として 3 年間勤務し、日本に帰国。帰国後、翻訳会社を知人と設立し、社長を 2 年間務めるが、売却して健康食品会社のアメリカ法人の総支配人として 2 年あまり勤務し、帰国。その後、フリーの翻訳者として活躍。 |
|
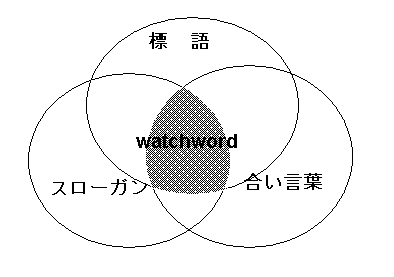
翻訳とは、他人がある言語で記述した概念を別の言語を話す人たちにその言語で伝達する作業である。したがって、翻訳者はそこで使われるソース言語とターゲット言語の2つの言語に堪能で、しかも書かれている内容についてそれを記述した人間と同じ程度の知識を要求される。 外国語の通訳や翻訳などの作業に携わったことのない一般の人たちは、英語や中国語ができれば、どのような内容であれ日本語に翻訳できると考えがちだが、実際にはソース言語の一般的な解釈力のほかに記述されている概念を理解するための知識が必要となる。これは、日本語でコンピュータに関する文章を読んで理解できない人は、いくら英語ができても英語でコンピュータに関する文章を読んでも理解できないという例を考えれば明らかだ。 したがって、英語から日本語に翻訳を行う典型的な翻訳者の場合を考えると、英文独特の発想や言い回しを理解するための英英辞典と英和辞典、そのほかに専門的な知識を補うための専門用語辞典の 2 種類の辞典が必要となる。 ところで、辞典を丹念に引くほどよい翻訳者といえるのだろうか。答えは必ずしも Yes ではない。理解できない語があるのに辞典をひくのを怠る翻訳者は論外だが、逆に辞典をひく必要のない翻訳者ほど優秀といえないだろうか。翻訳者の理想像を考えてみると、翻訳対象分野の知識が十分にあり、その分野の文章を自分で書く力があり、そしてその分野の英文はほとんど辞典をひかずに理解できる翻訳者ではないだろうか。実際に、力のある翻訳者は、短期間に高いレベルの翻訳を生産しているが、それは専門書も辞典もほとんど開かずに、ひたすら自分の頭に浮かぶ翻訳文を流れるようにキー入力できるから行える業である。 とはいえ、現実の世界では多くの翻訳者が多数の辞典を利用しており、しかも正しい利用法を心得ている翻訳者の数は意外と少ない。なぜそう言いきれるかというと、それは訳文を見て判断できるからである。訳文を見ると、その翻訳者が実際に翻訳をしている現場に立ち会わなくても、どの単語で引っかかり、辞典または辞典を調べ、その結果正しい訳語を選択できたのかどうかがわかる。 英和辞典の限界とその攻略法 英和辞典とは本来どのように作られているものだろうか。多くの辞典利用者は、必ず対象の単語の正しい訳語が辞典に出ていると確信して、あるいは今調べている辞典に適切な訳語がなくても、どこかに正しい訳語を載せた辞典があるはずだと考えて、いろいろな英和辞典をひいて見る。そして、たくさんの定義から最適と思われる訳語を選択する。このような考え方の人は辞典をできるだけ多くそろえることが正しい訳語を見つけるのに有利と考え、中には辞典マニアと化してあらゆる辞典を書棚に飾って満足感に浸るひともいる。しかし、これは正しい英和辞典の使い方だろうか。 ある国または地方の言語は、その地域の文化と切り離して考えることはできない。言語はその文化を背景に成長し、その文化の発想に基づいて言語が話されたり、書かれたりし、逆にその文化はその言語がなければ育たなかった習慣であり、風習である。したがって、ある外国語を学習するには、その背景にある文化を学習することが必須で、外国語の学習とは非常に人間くさい営みである。しかし、非常に残念なことに日本の学校における外国語教育は、外国語とその外国語が使われる地域の文化との強い結びつきを無視して、外国語を単なる記号ととらえている。単語という記号をできるだけ多く暗記し、それを文法という規則に従って並べれば、それで外国語を書いたり、話したりすることができ、文化などは関係ないという発想である。 長年このような学校教育を受けた日本人は、その長い学校生活の間に正しい辞典の使い方さえ習っていない。初学者にこの傾向が強いが、多くの翻訳者も、意味が分からない単語に出会ったときに英和辞典を引けば、必ず適切な「意味」が載っていると考えていないだろうか。したがって、ある辞典を引いてしっくりと当てはまる意味が載っていないと、さらに厚い辞典を引き、最後に何とか使える「意味」を無理に当てはめるという作業をした経験が多いのではないだろうか。この考え方は誤りであり、このような努力は最終的に徒労に終わる(できあがった翻訳文が、自然な日本語にならない)ことが多い。 上記のように、言語は人間のあらゆる営みに関係するものであり、記号のように無味乾燥に使われるのではなく、書き手は常に新しい表現を使って読む人の心をとらえようとしている。簡単な単語であっても、1つの単語は数百通り、数千通り、多分数万通りの使われ方をし、しかも日々変化しているのである。実は、学校でも先生から英和辞典で「意味」を調べなさいと習ったと思うが、実は英和辞典に記載されているのは「意味」ではなく、あくまでもある単語に関し、過去にこのような使われ方をした例が多いという「日本語の対応語」を示しているのであって、それは代表的な訳語が列挙してあるに過ぎない。 したがって、たまたま英和辞典に現在訳しているコンテキストにぴったりの対応語が載っていれば、ラッキーでそれを使えばいいわけだが、現実の翻訳ではしばしばいくら厚い英和辞典をひいても適切な訳語が見つからないことがある。たとえば、次の文は昨年7月号のPotpourriで取り上げた文だが、このwatchwordを英和辞典でひいてもせいぜい「標語」「スローガン」「合い言葉」くらいの対応語しか載っていない。そこで翻訳者は、このどれを訳語として使ったらいいか悩むことになる。 For the last 20 or so years, structure has been the watchword in computer programming. Structure has always been consistent with our view of computers. このコンテキストではこの3つの対応語からどれを選んでもしっくりした訳にはならない。それでも上記のように辞典の役割を誤解している多くの翻訳者は、watchwordにはこの3つの意味しかなく、そのどれかを選ばざるを得ないと考えて結果的に自然な日本語ではない翻訳をしてしまう。このような場合には、クイズのようにこの3つの対応語からこの単語の本来の「意味」を推測し、自分で適切な「対応語」を考え出さなければならないのである。 このようなときには、英英辞典をひかなければならない。なぜならば、英英辞典にこそ単語の「意味」が説明されているのである。たとえばCollins Cobuildでwatchwordをひくと"a word or phrase that sums up the way that a particular group of people should think or behave"と定義されている。つまり、これがwatchwordという単語の持つ意味であって、英和辞典にはこのような意味の説明がなく、単に代表的なケースで対応する日本語の対応語として上記の3例が記載されているに過ぎない。これを図示すると、次のようになり、英和辞典をひいた翻訳者は、watchwordという単語は「標語」、「スローガン」、「合い言葉」がすべて重なる部分の意味を持っていて、そのときどきで「標語」、「スローガン」、「合い言葉」、あるいはコンテキストに相応しいその他の訳語に訳せるのだということを知らなければならない。この3つの対応語が重なる部分の「単語本来の意味」は英英辞典で説明されているのである。
このような和英辞典と英英辞典の性質を理解していれば、その両方をひいた結果、「これまでの約 20 年間、コンピュータプログラミングに関しては構造が重視されてきた」くらいの訳文が浮かぶはずだ。このように英和辞典と英英辞典には本質的な性質の違いがあるので、英語学習者や翻訳者に和英辞典だけではなく英英辞典をひくことが薦められるのである。この2種類の辞典はクルマの両輪であって、片方だけでは不完全な翻訳しかできないのである。英和辞典のみにしがみついて正しい翻訳を目指そうとすれば、示された代表的な「対応語」例からその重なる部分にある本来の「意味」を推測するというクイズまがいの作業を強いられるのである。英和辞典の限界を乗り越えるためには英英辞典が必要なのである。 専門語辞典の限界と攻略法 専門語辞典の限界はまったく別のところにある。技術分野の専門用語の場合には、英和辞典と違って「対応語」イコール「訳語」となるのである。たとえば、cache という用語は、すべてのコンピュータ用語辞典に「キャッシュ」と出ているので、この対応語をそのまま使える。しかし、この場合にも「意味」を調べて、cache が何を意味するかを理解して訳すことが重要である。そうでないと、cache が動詞として使われているときに「キャッシュする」なのか「キャッシュを使う」なのか「キャッシュに入れる」なのかわからない。また、すべての専門用語が 1 つの対応語しかないわけではなく、control のように「コントロール」と「制御」、call のように「呼び出し」と「呼」など複数の対応語を持つものは、どちらの対応語を取ったらいいかわからない。それにコンピュータ関連分野と言っても、ハードウェア、コンピュータ言語、アプリケーション、オペレーティングシステム、ネットワーク、データベース、テレフォニと実に幅が広く、そのすべての分野で技術が急速に進歩しており、かつ技術翻訳の対象は常に最新のテクノロジである。このため翻訳に必要な知識の吸収に、相当の時間を割く必要が出てきた。 さらに、すべての技術分野でコンピュータ化が進み、技術翻訳分野でコンピュータ用語の占める割合が多くなったため、技術の進歩に辞典が追いつかなくなり、現在使われている専門用語を網羅した技術用語辞典はあり得なくなってしまった。つまり、辞典に対応語が載っていれば、それを使える場合が多いにもかかわらず、必要な専門用語が載っている辞典がない、その意味を説明した辞典がないのである。これが、専門用語辞典の限界である。 しかし、同じコンピュータ分野の進歩がこの限界を攻略する方法を与えてくれた。それが、インターネット上での検索である。現在、コンピュータ分野に特化している翻訳者は、すべて専門用語辞典をひくよりもインターネット上で検索する方が多いのではないだろうか。たとえば、マイクロソフト関連のジョブであればマイクロソフトの Web ページ、IBM 関連のジョブであれば IBM の Web サイトに製品説明や、ベンダーによっては用語集までアップされている。 これと並んで重要な役割を果たしてくれるのが、クライアント提供の専門用語集で、それによって新しい用語の訳語を指定されたり、interface を「インターフェイス」、「インタフェース」、「インターフェース」のどれに訳したらいいかが指定される。 コンピュータ分野では、最近では翻訳会社よりもローカライザからジョブを受けることが多くなった。この場合には、翻訳者は最終製品の提出を求められるので、わからない用語に出会えば、それをローカライザにたずねて訳語をフィックスする必要がある。このとき、どのような質問をするかで、その翻訳者が十分なインターネット上での検索能力を持っているか、基礎的なコンピュータ関連の知識を持っているかが判断されてしまう。 辞書の概念 上記で Web 検索について触れたが、Web 上の辞書や電子辞書など、辞書のデジタル化により、辞書の概念が大きく変化した。辞書とは「あいうえお」順、あるいは「abc」順に見出し語が並んでいるのが当たり前と考えがちだが、これは紙の辞書しかなかった時代の概念だ。たとえば、Encartaや CD ROM Britannica、Readers Plus や Random House など、CD-ROM 版のエンサイクロペディアや辞典になると、見出し語だけではなく、見出し語となっていない本文中の単語も検索することができる。そうなると、検索は調べたい用語を入力して検索するので、用語説明が「あいうえお」順や「abc」順に並んでいる必要はない。その結果、BusinessWeek やコンピュータ関連の雑誌のバックナンバーの CD-ROM でも単語を検索することができ、自分で用語集を作成するときでも、必要な文例を片っ端から集めて 1 つのファイルに入れておけば、それを一定の順序に並べるという面倒で時間のかかる作業は不要で、そうしなくても秀丸や WZ などのエディタにある grep 機能を使って検索できる。便利な機能は徹底的に利用しよう。 電子辞書や Web サイトでの検索方法 最後に上記のような電子辞書、電子エンサイクロペディア、および Web 上での検索エンジンでの検索方法について簡単に説明しよう。多くの翻訳者は単に単語を 1 つ入力して検索しているのではないだろうか。それでは、検索機能のほんの一部しか使っていない。 まず、電子辞書のたぐいだが、通常はデフォルトで「前方一致検索」に設定されており、たとえば some と入力すると some のほかに something や somebody も引っかかる。これを「後方一致検索」に切り替えると threesome や troublesome もひくことができる。 また、最近はハードディスクの容量が大きくなり、「CD 革命」などのソフトを使うと本来ハードディスクにインストールできない辞書でもハードディスクに格納できるので、複数の辞書をハードディスクに入れている翻訳者も多いだろう*。その場合には、DDWIN や PDIC などの検索ソフトを使うと複数の辞書を「串刺し検索」できて便利だ。 そして、多くの辞書や検索ソフト、そして Web 上の検索エンジンでは、and、or、not、adj などのブール演算子を使用できる。たとえば、word search という句の説明を知りたいときに、多くの方は検索フィールドに word search と 2 つの単語をスペースで区切って入力しているのではないだろうか。こうすると、多くの場合 or 演算子を指定したことになり、word か search を含む(説明)文がひっかかる。この 2 つの単語が一緒に含まれている文を探すには 2 つの単語の間に and か + 記号が必要だ。2 つの単語の間に not を入れると word を含んで search は含まない文が検索できる。そして 2 つの単語の間に adj や near を入れると、指定した 2 つの単語が5語以内にくっついて出てくる文が検索される。ただし、検索ソフトや検索エンジンによって使い方が少しずつ異なるので、よく使うツールについては一度はヘルプを見て検索方法を調べておくといい。ルールの数は少なく、しかも一度覚えれば非常に効率的に検索できる。これもデジタル時代の翻訳者に求められているスキルのひとつだ。 * 注: コンピュータ翻訳では、デスクトップ上で翻訳を行い、関連資料や辞書は横に置いたラップトップで調べるのが効率的だ。ラップトップに CD 革命と辞書検索ソフトを利用して多くの辞書を積んでおけば、ときには気分転換にラップトップを持って出かけて別の場所で翻訳もできる。総合的な効率化で生産性を上げて収入増をはかろう。 |
 トップページ |
 翻訳論目次 |
 メール |
